
In April 2023, Runway AI, founded in New York City, released a video generated with AI: blurry and jerky, with distorted objects, and only four seconds long;
Four months later, Runway pulled the video effects of the Vincennes video up to the hyper-compelling heights of 4K, achieving coherent stabilization of the footage. The maximum length of the video was also increased from 4 seconds to 18 seconds – the “length ceiling” for Vincent’s videos in 2023.
However, in the early morning of February 16, 2024 , the “ceiling” has been broken again – OpenAI has made another bomb, released the AI model Sora that can generate 60-second videos.

Gemini Pro 1.5, Google’s latest multimodal model, also released on February 16th, was quickly losing attention to Sora.
According to OpenAI’s official tweets and technical reports, the revolutionary nature of Sora’s capabilities can be summarized as: generating up to 60s of video, consistency in front and back of the camera, and ultra-realism.
From the official video demo, Sora only needs to input the Prompt (prompt) containing “composition elements, environment, behavior and sequence of occurrence, video style” and other key factors, and then can generate different styles of high-definition, coherent, and with a rich operation of the camera and transitions of the 60s level video.
For example, to generate videos containing characters and city elements:
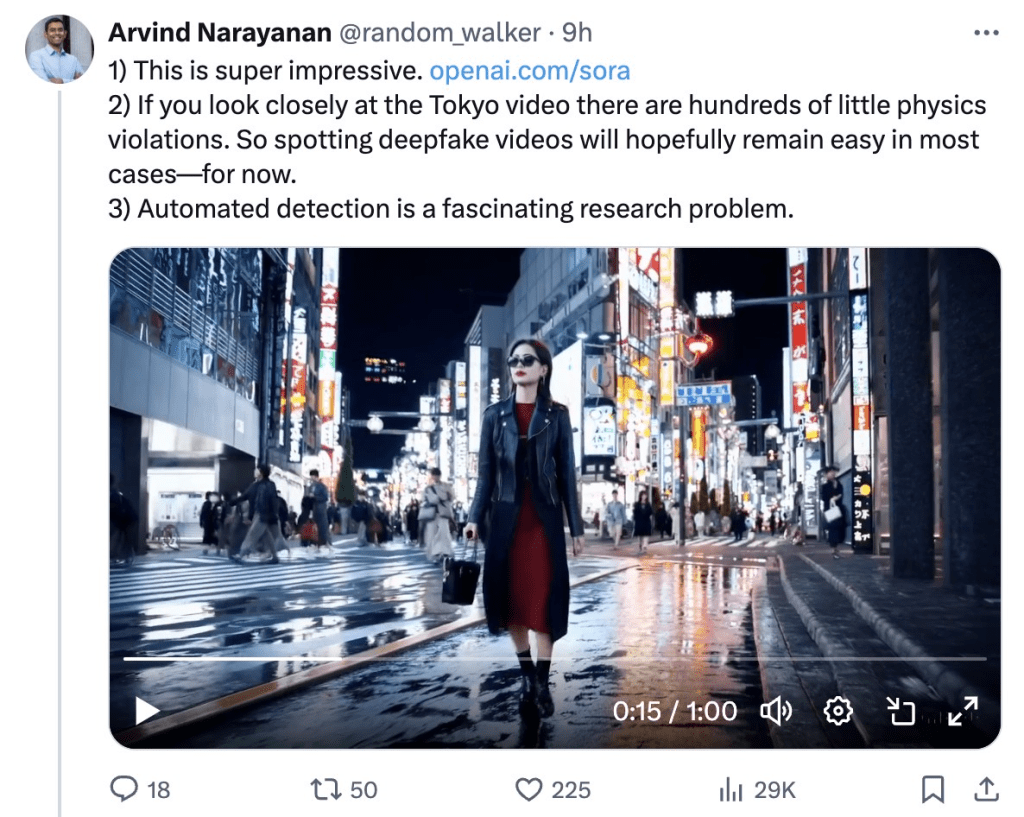
Cue word: A stylish woman walks down a Tokyo street filled with warm neon lights and animated city signs. She is wearing a black leather jacket, a long red dress and black boots and carrying a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is wet and reflective, mirrored by colored lights. Many pedestrians walk around.

Sora can also generate animals and nature scenes:
Cue word: several huge woolly mammoths approaching on a snowy meadow, their long shaggy pelts fluttering gently in the wind, snow-covered trees and majestic snow-covered mountains in the distance, wisps of clouds in the afternoon sunlight, the sun hanging high in the sky at a distance to produce a warm glow, the low camera view stunningly captures the large woolly mammals with beautiful photography and depth of field.

The videos generated by Sora are already capable of achieving realistic results. However, generating virtual scenes in 3D and anime style is no problem for Sora:
Cue word: The animated scene features a close-up of a small furry monster kneeling next to a melting red candle. The art style is 3D and realistic with a focus on lighting and textures. The mood of the painting is one of wonder and curiosity as the monster gazes into the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.

Breaking the bottleneck of duration and fidelity, Sora touches DALL-E to cross the river
Half a year ago, the duration under the premise of guaranteeing the generated picture quality was just breaking 10 seconds, which is an unattainable height for most video models.
This is due to the fact that mainstream video modeling paradigms such as recurrent networks, generative adversarial networks, Diffusion models, etc., usually can only learn a small class of visual data, shorter videos, or fixed-size videos.
This means that the video generation models in the previous mainstream paradigms have high requirements on the training data, which need to be processed into videos with standard size and cropped dimensions.
Sora’s technical report shows that in order to build Sora, OpenAI innovatively used techniques related to the Vincennes graph model DALL-E 3: combining the Diffusion model (which can roughly transform random pixels into images) with the Transformer neural network (which supports processing long data sequences).
This means that Sora can understand and analyze visual data in chunks as if it were text and image data, without standardized pre-processing.
For example, in the same way that text is partitioned into the smallest processing unit, the token, in the large language model, Sora also compressed the video into lower dimensions and partitioned the visual data into patches that can be processed in chunks. The quality of video generation improves significantly as the amount of training computation is scaled up.
Training based on raw data rather than standardized processing data not only allows Sora to initially have the ability to understand the real or virtual world, but also has the flexibility to generate videos with different lengths, resolutions, and sizes (the current range of sizes that can be generated is: widescreen 1920x1080p~vertical 1080x1920p) to adapt to different scenarios and devices.

Still, there are many experts who view this technological breakthrough with caution. Ted Underwood, a professor of information science at the University of Illinois at Urbana-Champaign, said in an interview with the Washington Post that OpenAI might pick and choose some videos that would demonstrate the model’s best performance.
Then again, Arvind Narayanan, a professor of computer science at Princeton University, pointed out in an X tweet that a Sora-generated video of a stylish woman walking down a Tokyo street shows the woman’s left and right legs swapping places, and the figure in the background disappearing after being briefly obscured by a forward object.
OpenAI has also released some “Sora Rollover Videos” that show Sora’s weaknesses in understanding the physics, cause and effect, spatial details, and time lapse of complex scenes. For example, it reverses the direction of a person running on a treadmill.

Sora kills the Runways. Ethical Safety Raises Public Concerns
In 2022, the average length of TikTok’s Top 10 viewed videos was 44.2 seconds, with the longest one being 2 minutes and 16 seconds long;
Statistics from ad analytics firm Integral Ad Science show that the average duration of mobile web display ads and ads on mobile apps is 15.6 seconds and 20.2 seconds, respectively.
This means that once the Vincennes video model breaks through the 60s duration bottleneck and the picture quality reaches commercial grade, it will have a huge impact on the way users produce and entertain themselves. Michael Gracey, director of King of the Circus, told the Washington Post, “Filmmakers no longer need a team of 100 or 200 artists to produce their animated feature film in three years. That excites me.”
However, he remains concerned about the copyright disputes, and unemployment that AI tools may cause, “It [AI] is not good when it [AI] takes away other people’s creativity, work, ideas and execution without giving them the credit and financial compensation they deserve.”
As the quality of the videos generated by Sora is much higher than most video generation models, and the realistic style, in particular, makes it difficult to distinguish between the real and the fake, several experts have also voiced their concerns about Deepfake (video fakery). Oren Etzioni, a professor at the University of Washington and founder of True Media, an organization that identifies political campaign disinformation, said in an interview with the New York Times, “I’m very afraid that this kind of thing could affect a neck-and-neck election.”
Currently, OpenAI automatically adds watermark tags to videos generated by Sora to indicate that they were generated by AI.OpenAI founder and CEO Sam Altman said on X that Sora is currently running Red-Teaming, a security assessment method, and that the test is only open to a small number of people.

However, even if it’s not yet officially available to the public, Sora’s capabilities have already caused a lot of panic among video modeling entrepreneurs.
No one wants to use the ‘Runway guys’ when a video model with better quality, longer duration, and a wider range of application scenarios is in front of them.
